![[TIL-20240813-17] Elasticsearch 자동 완성 (2)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FvmkzZ%2FbtsI1oRKlA5%2FAAAAAAAAAAAAAAAAAAAAAKTQSqMTJllD4MVCKzf-AALgO7v6zYGilELpts1WYpIw%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1774969199%26allow_ip%3D%26allow_referer%3D%26signature%3DEZ%252BEUMJZnrafesQCkaVtMh%252F7uKc%253D)

https://yeon-dev.tistory.com/254
[TIL - 20240810] ElasticSearch 자동 완성 (1)
https://yeon-dev.tistory.com/253 [Spring] Spring Boot3.x Docker Compose로 ElasticSearch 8.x+Kibana 구성 (Local)프로젝트 루트 디렉토리에 docker-compose.yml을 생성한다. 1. Docker Compose 파일 작성docker-compose.ymlversion: '3.7'servi
yeon-dev.tistory.com
💻문제점1 - 검색 결과 우선 순위
PostMan으로 요청하면 응답이 다음과 같다.
http://localhost:8080/api/v1/posts/suggest?keyword=맛있는 통밀빵[
"통밀빵 정말 맛있는 카페",
"맛있는 통밀빵 간식 만들기",
"맛있는 비건 디저트 카페",
"통밀빵 맛있게 먹는 방법",
"통밀 식빵 맛있게 먹는 방법",
"통밀빵 효능",
"감성빵집 통밀빵",
"통밀빵 샌드위치",
"100% 통밀빵 토스트",
"스완베이커리 통밀빵",
"파리바게트 통밀빵 다이어트"
]"맛있는 통밀빵 간식 만들기"가 검색어와 일치하는 구문이 있음에도 2번째로 위치한다.
또한, "맛있는 비건 디저트 카페"는 "통밀 식빵 맛있게 먹는 방법" 보다 우선 순위가 높다.
📃문제점1 시도
1. Kibana 콘솔
GET /posts/_search
{
"size": 5,
"query": {
"bool": {
"should": [
{
"match_phrase": {
"title": {
"query": "맛있는 통밀빵",
"slop": 1,
"boost": 3.0
}
}
},
{
"match": {
"title.ngram": {
"query": "맛있는 통밀빵",
"operator": "and",
"boost": 2.0
}
}
}
],
"minimum_should_match": 1
}
}
}1. Bool Query
여러 쿼리를 결합하는데 사용한다. 상위에 bool 쿼리를 사용하고, 그 안에 다른 쿼리를 넣어 사용할 수 있다.
- must: 쿼리가 참인 문서 검색
- must_not: 쿼리가 거짓인 문서 검색
- should: 검색 결과 중 이 쿼리에 해당하는 문서의 점수를 높임
- filter: 쿼리가 참인 문서를 검색하지만, 스코어를 계산하지 않음
위에서는 should를 사용하여 두 개의 조건을 정의하고 있다.
minimum_should_match: 1로 설정하여, 두 조건 중 하나라도 일치하면 문서를 반환한다.
2. should
2-1. match_phrase 쿼리
match_phrase 쿼리는 검색어의 단어가 모두 존재하고, 순서가 같은 문서를 반환한다.
- slop: 1
- slop은 단어 사이에 허용되는 단어 개수를 의미한다.
- slop: 1을 통해 "맛있는 통밀빵"을 입력했을 때, 예를 들어 "맛있는 최고의 통밀빵"도 조건을 만족할 수 있다.
- boost: 3.0
- boost는 조건의 중요도를 의미한다.
- match_phrase 조건에 높은 boost를 설정하여, 이 조건을 만족하면 가장 높은 우선 순위를 갖도록 했다.
2-2. match 쿼리
N-gram 분석기를 사용하는 titme.ngram 필드에서 검색을 수행한다.
- operator: "and"
- 모든 단어가 문서에 포함되어야 결과에 포함된다.
- boost: 2.0
- match_phrase 보다는 낮은 우선 순위를 갖는다.
2. 서비스, 레포지토리 코드
PostCustomElasticRepositoryImpl
@Repository
@RequiredArgsConstructor
public class PostCustomElasticRepositoryImpl implements PostCustomElasticRepository {
private final ElasticsearchClient elasticsearchClient;
private final String POST_INDEX = "posts";
@Override
public List<PostDocument> findAutoCompleteSuggestion(String keyword, int size) {
try {
SearchResponse<PostDocument> response = elasticsearchClient.search(s -> s
.index(POST_INDEX)
.size(size)
.query(q -> q
.bool(b -> b
.should(sh -> sh
.matchPhrase(mp -> mp
.field("title")
.query(keyword)
.slop(1)
.boost(3.0f)
)
)
.should(sh -> sh
.match(m -> m
.field("title.ngram")
.query(keyword)
.operator(Operator.And)
.boost(2.0f)
)
).minimumShouldMatch("1")
)
), PostDocument.class
);
return response.hits().hits().stream()
.map(Hit::source)
.toList();
} catch (IOException e) {
throw new ElasticsearchOperationException(ErrorCode.ES_OPERATION_FAILED);
}
}
}
PostQueryService
public List<String> suggestByKeyword(String keyword, int size) {
return postElasticRepository.findAutoCompleteSuggestion(keyword, size)
.stream()
.map(PostDocument::getTitle)
.toList();
}
ES 검색 도중 LocalDateTime 직렬화/역직렬화 문제가 있었다. 자세한 내용은 다음 링크에서 확인할 수 있다.
https://yeon-dev.tistory.com/256
[TIL - 20240817] Spring Boot 3.x + Elasticsearch 8.x jackson.databind.exc.InvalidDefinitionException: Java 8 date/time type `jav
💻문제점 - LocalDateTime 직렬화/역직렬화Elasticsearch 검색을 수행하던 도중 오류가 발생했다.http://localhost:8080/api/v1/posts/suggest?keyword=통밀빵 com.fasterxml.jackson.databind.exc.InvalidDefinitionException: Java 8 d
yeon-dev.tistory.com
PostMan으로 요청을 보내보자.
size는 디폴트 값(=5)이 설정되어 있어서 요청 파라미터에 포함하지 않았다.
http://localhost:8080/api/v1/posts/suggest?keyword=맛있는 통밀빵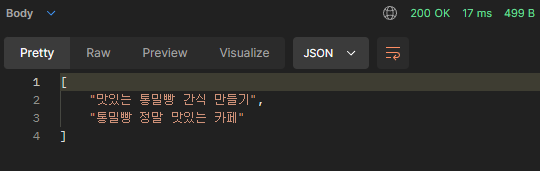
"맛있는 비건 디저트 카페"
- 두 가지 조건 모두 맞지 않아 결과에 포함되지 않는다.
우선 순위
- 검색어와 일치하는 구문이 있는 "맛있는 통밀빵 간식 만들기"가 가장 위에 위치한다. (조건1 충족)
- "통밀빵"과 "맛있는"이 포함된 "통밀빵 정말 맛있는 카페"가 그 다음에 위치한다. (조건2 충족)
"통밀빵 맛있게 먹는 방법"은 결과에 포함되지 않는다. "맛있는"이 아닌 "맛있게"가 포함되어 있기 때문이다.
하지만 검색어와 유사하므로 결과에 포함될 필요가 있었다.
🔍문제점1 해결
1. match 쿼리(Nori 분석기 사용) 추가
GET /posts/_search
{
"size": 10,
"query": {
"bool": {
"should": [
{
"match_phrase": {
"title": {
"query": "맛있는 통밀빵",
"slop": 1,
"boost": 3.0
}
}
},
{
"match": {
"title.nori": {
"query": "맛있는 통밀빵",
"operator": "and",
"boost": 2.0,
"fuzziness": 1
}
}
}
],
"minimum_should_match": 1
}
}
}
결과:
[
"맛있는 통밀빵 간식 만들기",
"맛있는 최고의 통밀빵 레시피",
"통밀빵 정말 맛있는 카페",
"통밀빵 맛있게 먹는 방법",
"통밀 식빵 맛있게 먹는 방법"
]1-1. match 쿼리
Nori 분석기를 사용하는 title.nori 필드에서 검색을 수행한다.
Nori 분석기의 nori_part_of_speech 필터를 사용해 "맛있는 통밀빵" 에서 '는'과 같은 조사를 제거하고 분석하기 위함이다.
- fuzziness: 1
- fuzziness는 두 문자열 사이의 최소 편집 작업(삽입/제거/변경/인접한 두 문자 교체) 수를 의미한다.
- 변경 (box → fox)
- 제거 (black → lack)
- 삽입 (sic → sick)
- 인접한 두 문자 교체 (act → cat)
- fuzziness가 없을 때, 만약 검색어가 "멋있는 통밀빵"이라면 아무런 문서도 반환되지 않을 것이다.
하지만 fuzziness: 1을 통해 한 글자의 오타를 허용하기 때문에, "멋있는 통밀빵" 이라고 검색해도 다음과 같은 결과를 반환한다.
- fuzziness는 두 문자열 사이의 최소 편집 작업(삽입/제거/변경/인접한 두 문자 교체) 수를 의미한다.
[
"통밀빵 정말 맛있는 카페",
"맛있는 통밀빵 간식 만들기",
"통밀빵 맛있게 먹는 방법",
"맛있는 최고의 통밀빵 레시피",
"통밀 식빵 맛있게 먹는 방법"
]
2. match 쿼리(N-gram 분석기 사용) 추가
GET /posts/_search
{
"size": 10,
"query": {
"bool": {
"should": [
{
"match_phrase": {
"title": {
"query": "맛있는 통밀빵",
"slop": 1,
"boost": 3.0
}
}
},
{
"match": {
"title.nori": {
"query": "맛있는 통밀빵",
"operator": "and",
"boost": 2.0,
"fuzziness": 1
}
}
},
{
"match": {
"title.ngram": {
"query": "맛있는 통밀빵"
}
}
}
],
"minimum_should_match": 1
}
}
}
결과:
[
"맛있는 통밀빵 간식 만들기",
"맛있는 최고의 통밀빵 레시피",
"통밀빵 정말 맛있는 카페",
"통밀빵 맛있게 먹는 방법",
"통밀 식빵 맛있게 먹는 방법",
"맛있는 비건 디저트 카페",
"통밀빵 효능",
"감성빵집 통밀빵",
"통밀빵 샌드위치",
"100% 통밀빵 토스트"
]2-1. match 쿼리
N-gram 분석기가 적용된 title.ngram 필드에서 부분 문자열을 기반으로 유사한 문서를 찾는다.
이 쿼리문으로 인해 "맛있는 통밀빵"을 입력했을 때 "맛있는 비건 디저트 카페"나 "통밀빵 효능"과 같이 부분 문자열이 일치하는 경우도 결과에 포함된다.
때문에 관련이 적은 결과가 포함될 수 있어 앞선 2개의 조건 보다 낮은 우선 순위를 갖도록 했다. (디폴트 1.0)
3. 서비스, 레포지토리 코드
PostCustomElasticRepositoryImpl
@Repository
@RequiredArgsConstructor
public class PostCustomElasticRepositoryImpl implements PostCustomElasticRepository {
private final ElasticsearchClient elasticsearchClient;
private final String POST_INDEX = "posts";
@Override
public List<PostDocument> findAutoCompleteSuggestion(String keyword, int size) {
try {
SearchResponse<PostDocument> response = elasticsearchClient.search(s -> s
.index(POST_INDEX)
.size(size)
.query(q -> q
.bool(b -> b
.should(sh -> sh
.matchPhrase(mp -> mp
.field("title")
.query(keyword)
.slop(1)
.boost(3.0f)
)
)
.should(sh -> sh
.match(m -> m
.field("title.nori")
.query(keyword)
.operator(Operator.And)
.boost(2.0f)
.fuzziness("1")
)
)
.should(sh -> sh
.match(m -> m
.field("title.ngram")
.query(keyword)
)
).minimumShouldMatch("1")
)
), PostDocument.class
);
return response.hits().hits().stream().map(Hit::source).toList();
} catch (IOException e) {
throw new ElasticsearchOperationException(ErrorCode.ES_OPERATION_FAILED);
}
}
}PostMan으로 요청해보았다.
http://localhost:8080/api/v1/posts/suggest?keyword=맛있는 통밀빵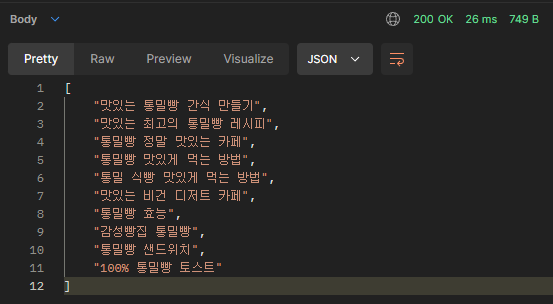
1. match_phrase 쿼리만 사용된 결과
["맛있는 통밀빵 간식 만들기", "맛있는 최고의 통밀빵 레시피"]
2. match 쿼리(Nori 분석기 사용) 추가한 결과
["맛있는 통밀빵 간식 만들기", "맛있는 최고의 통밀빵 레시피",
"통밀빵 정말 맛있는 카페", "통밀빵 맛있게 먹는 방법", "통밀 식빵 맛있게 먹는 방법"]
3. match 쿼리(Ngram 분석기 사용) 추가한 결과
["맛있는 통밀빵 간식 만들기", "맛있는 최고의 통밀빵 레시피",
"통밀빵 정말 맛있는 카페", "통밀빵 맛있게 먹는 방법", "통밀 식빵 맛있게 먹는 방법",
"맛있는 비건 디저트 카페", "통밀빵 효능", "감성빵집 통밀빵", "통밀빵 샌드위치", "100% 통밀빵 토스트"]💻문제점2 - 가독성
현재 findAutoCompleteSuggestion 메서드는 람다 표현식이 중첩되어 있어서 Spotless를 사용하여 코드 포맷팅을 하면 가독성이 매우 떨어진다.
@Override
public List<PostDocument> findAutoCompleteSuggestion(String keyword, int size) {
try {
SearchResponse<PostDocument> response =
elasticsearchClient.search(
s ->
s.index(POST_INDEX)
.size(size)
.query(
q ->
q.bool(
b ->
b.should(
sh ->
sh
.matchPhrase(
mp ->
mp.field(
"title")
.query(
keyword)
.slop(
1)
.boost(
3.0f)))
.should(
sh ->
sh
.match(
m ->
m.field(
"title.nori")
.query(
keyword)
.operator(
Operator
.And)
.boost(
2.0f)
.fuzziness(
"1")))
.should(
sh ->
sh
.match(
m ->
m.field(
"title.ngram")
.query(
keyword)))
.minimumShouldMatch(
"1"))),
return response.hits().hits().stream().map(Hit::source).toList();
} catch (IOException e) {
throw new ElasticsearchOperationException(ErrorCode.ES_OPERATION_FAILED);
}
}🔍문제점2 해결
@Repository
@RequiredArgsConstructor
public class PostCustomElasticRepositoryImpl implements PostCustomElasticRepository {
private final ElasticsearchClient elasticsearchClient;
private final String POST_INDEX = "posts";
@Override
public List<PostDocument> findAutoCompleteSuggestion(String keyword, int size) {
try {
SearchResponse<PostDocument> response =
elasticsearchClient.search(
s -> autoCompleteSuggestionQuery(s, keyword, size), PostDocument.class);
return response.hits().hits().stream().map(Hit::source).toList();
} catch (IOException e) {
throw new ElasticsearchOperationException(ErrorCode.ES_OPERATION_FAILED);
}
}
private ObjectBuilder<SearchRequest> autoCompleteSuggestionQuery(
SearchRequest.Builder builder, String keyword, int size) {
Query matchPhraseQuery = MatchPhraseQuery.of(mp -> mp.field("title").query(keyword).slop(1).boost(3.0f))._toQuery();
Query matchNoriQuery = MatchQuery.of(m -> m.field("title.nori").query(keyword).operator(Operator.And).boost(2.0f).fuzziness("1"))._toQuery();
Query matchNgramQuery = MatchQuery.of(m -> m.field("title.ngram").query(keyword))._toQuery();
Query boolQuery = BoolQuery.of(b -> b.should(matchPhraseQuery).should(matchNoriQuery).should(matchNgramQuery).minimumShouldMatch("1"))._toQuery();
return builder.index(POST_INDEX).size(size).query(boolQuery);
}
}쿼리 작성 로직을 메서드로 분리하고, MatchPhraseQuery, MatchQuery, BoolQuery를 따로 작성했다.
이를 결합하여 최종 쿼리를 생성한다.
Spotless를 적용하면 다음과 같이 포맷팅된다. 이전과 비교했을 때 가독성이 더 좋아졌다.
private ObjectBuilder<SearchRequest> autoCompleteSuggestionQuery(
SearchRequest.Builder builder, String keyword, int size) {
Query matchPhraseQuery =
MatchPhraseQuery.of(mp -> mp.field("title").query(keyword).slop(1).boost(3.0f))
._toQuery();
Query matchNoriQuery =
MatchQuery.of(
m ->
m.field("title.nori")
.query(keyword)
.operator(Operator.And)
.boost(2.0f)
.fuzziness("1"))
._toQuery();
Query matchNgramQuery =
MatchQuery.of(m -> m.field("title.ngram").query(keyword))._toQuery();
Query boolQuery =
BoolQuery.of(
b ->
b.should(matchPhraseQuery)
.should(matchNoriQuery)
.should(matchNgramQuery)
.minimumShouldMatch("1"))
._toQuery();
return builder.index(POST_INDEX).size(size).query(boolQuery);
}